

Last time we looked at some generic diagrams from the C4 model, which are useful for most teams. This time we’re going to explore a more specific type of diagram that can be a tremendous help with security.
Data Flow Diagrams
A Data Flow Diagram (DFD), as the name indicates, shows the flow of data through the system. It depicts external entities, processes, data stores, and data flows. Larger systems usually have composite processes, which expand into their own DFD.
Here’s a simple example of a data flow diagram:

Create a Data Flow Diagram from a Container Diagram
If you already have a container diagram of your system, then it’s easy to create a DFD from it:
- Convert containers into processes by drawing them as circles. You may or may not want to number them. Complicate containers with many processes running in them may be modeled as composite process that expand into their own sub-DFD.
- Convert external systems into external entities by drawing them as rectangles.
- Convert databases and queues into data stores by drawing them as horizontal parallel bars.
- Modify the directions of all the arrows as needed. In a container diagram, the direction of an arrow usually indicates who initiates a request. In a data flow diagram, the direction of an arrow indicates the direction in which data flows. This could be both ways.
Some people use arrows to indicate data flows in container diagrams as well. In that case, you don’t have anything to do in this step.
Now, why would you go through the trouble to convert a container diagram into a DFD? There are several uses for DFDs, but in this post I want to focus on using them for threat modeling.
Threat Models
In threat modeling, we look for design flaws with security implications. These are different from implementation bugs, which makes them hard to detect using code-based techniques such as Static Application Security Testing (SAST) or security code reviews. But the flip side of that is that you can do threat modeling even before any code is written. And you should!
Threat modeling falls under Threat Assessment in the Software Assurance Maturity Model.
There are many ways to do build threat models, but the one I’ve found easiest to understand for developers with limited security knowledge (which is the vast majority), is to use STRIDE, an acronym for the types of security threats that exist:
- Spoofing
- Tampering
- Repudiation
- Information disclosure
- Denial of service
- Elevation of privilege
Using DFDs to Build Threat Models
Not all of the STRIDE threats are applicable to all elements of our system, and this is where the DFD comes in handy, since each DFD element maps nicely unto some subset of the STRIDE threats:

So now you have a structured process for reviewing your architecture from a security perspective:
- Create a DFD from your container diagram (or from scratch if you don’t have one)
- Identify the threats using STRIDE
- Score the threats using the Common Vulnerability Scoring System (CVSS)
- Manage the risks posed by the identified threats:
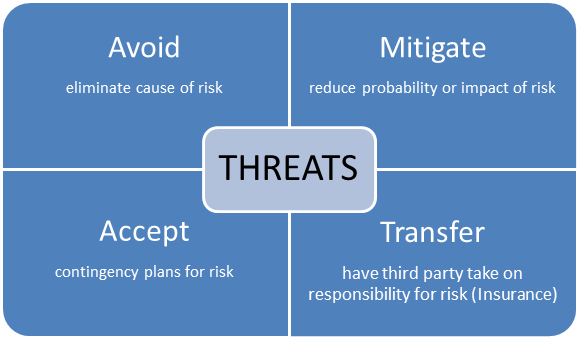
I’ve found that using CVSS scores for threats makes it easier to decide how to manage them. You can set a security risk appetite for your system, for example accept threats in the None through Medium levels and work to avoid or mitigate High or Critical levels.
CVSS scores also go a long way towards making the threat assessment objective, which makes it easier to convince people that work should be done to reduce the security risk.
Costs and Benefits of Threat Models
If all of this seems like a lot of work, especially for a big system, that’s because it is. Sorry.
It’s not quite as bad as it may seem, however, because DFD elements can usually be grouped since they all behave the same from a security perspective. So then you only have to score and manage the group as a whole rather than all the elements in it individually. But still, threat modeling is a considerable investment.
When I’ve done this activity with developers, I see that it always provides a lot of value. We usually find one or more security threats that we really need to manage better. And most of the time participants get a much better understanding of their system, which helps them in their non-security work as well.
What do you think? Is threat modeling using data flow diagrams and STRIDE something you’re willing to give a shot, or do you prefer a method that requires less work (but offers less protection), like abuse cases? Please leave a comment.

 I’ve been a fan of the
I’ve been a fan of the  Last time, I wrote about
Last time, I wrote about  If your organization doesn’t have something like our PSO, you can look elsewhere. (And if it does, you should look outside too!)
If your organization doesn’t have something like our PSO, you can look elsewhere. (And if it does, you should look outside too!) You may think you know very little yet, but even then it’s valuable to share.
You may think you know very little yet, but even then it’s valuable to share.
 The SaaS platform I’m working on has a RESTful interface that accepts XML payloads.
The SaaS platform I’m working on has a RESTful interface that accepts XML payloads. We could rely on
We could rely on  If we can’t use schema validation, then what about using JSR 303
If we can’t use schema validation, then what about using JSR 303 
 In this approach, primitive types are replaced with value objects. (Some people even
In this approach, primitive types are replaced with value objects. (Some people even 
 There are many good reasons to use code written by others in your application.
There are many good reasons to use code written by others in your application.
 Chapter 5, Handling Input, describes how programs should deal with untrustworthy input.
Chapter 5, Handling Input, describes how programs should deal with untrustworthy input. Chapter 11, Privacy and Secrets, switches the focus from
Chapter 11, Privacy and Secrets, switches the focus from 
 One of the important things in a
One of the important things in a  The process outlined above works well for making our software ever more secure.
The process outlined above works well for making our software ever more secure. Some people object to the Zero Defects mentality, claiming that it’s unrealistic.
Some people object to the Zero Defects mentality, claiming that it’s unrealistic.
 He checks the accounting software and discovers that one account’s computer time is not paid for.
He checks the accounting software and discovers that one account’s computer time is not paid for.
 The attacker used this to install his own copy of the
The attacker used this to install his own copy of the 
You must be logged in to post a comment.